Last year – 2022 – was the year of Generative AI – the result of smart folks across the industry combining and building upon the techniques introduced in the papers “Improving Language Understanding by Generative Pre-Training” (Radford, Narasimhan, Salimans, and Sutskever, 2018) [2] and “Deep Reinforcement Learning from Human Preferences” (Christiano, et al) [3]. This family of generative, pre-trained transformer (GPT) models, including OpenAI’s ChatGPT and Google’s Bard, introduced a new approach to solving natural language-based problems. This novel pre-training is supported by unsupervised training on a large corpus of textual information through a large, transformer-based neural network, then, following that process with another round of training where the output is tuned based on human selection of multiple model outputs. This new technique produces foundation models which can respond appropriately to a wide variety of inputs and offers us an opportunity to evaluate GPT-based architectures and approaches to digest textual information such as Owner’s Manuals with hundreds of pages.
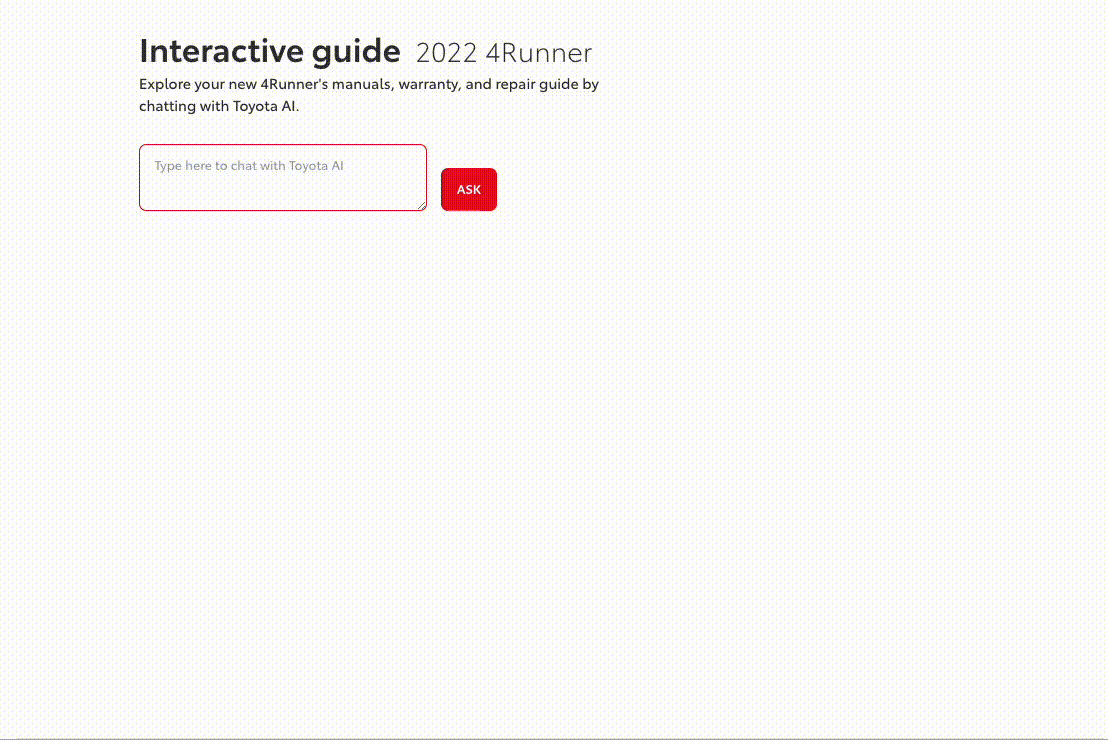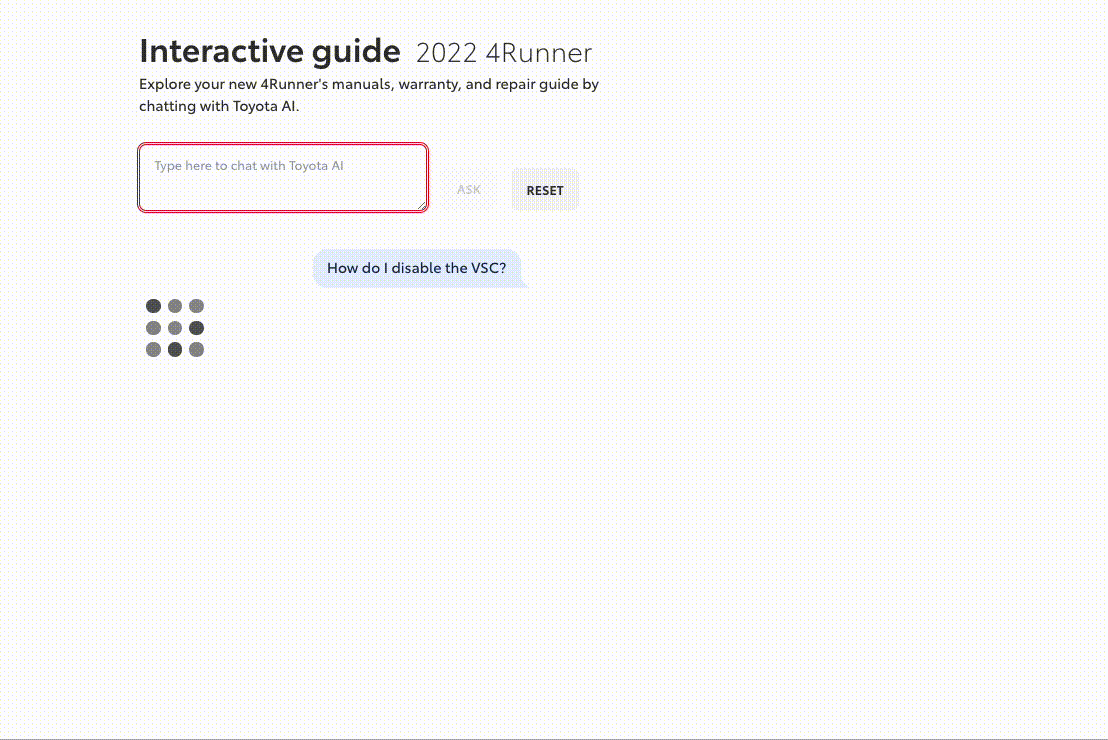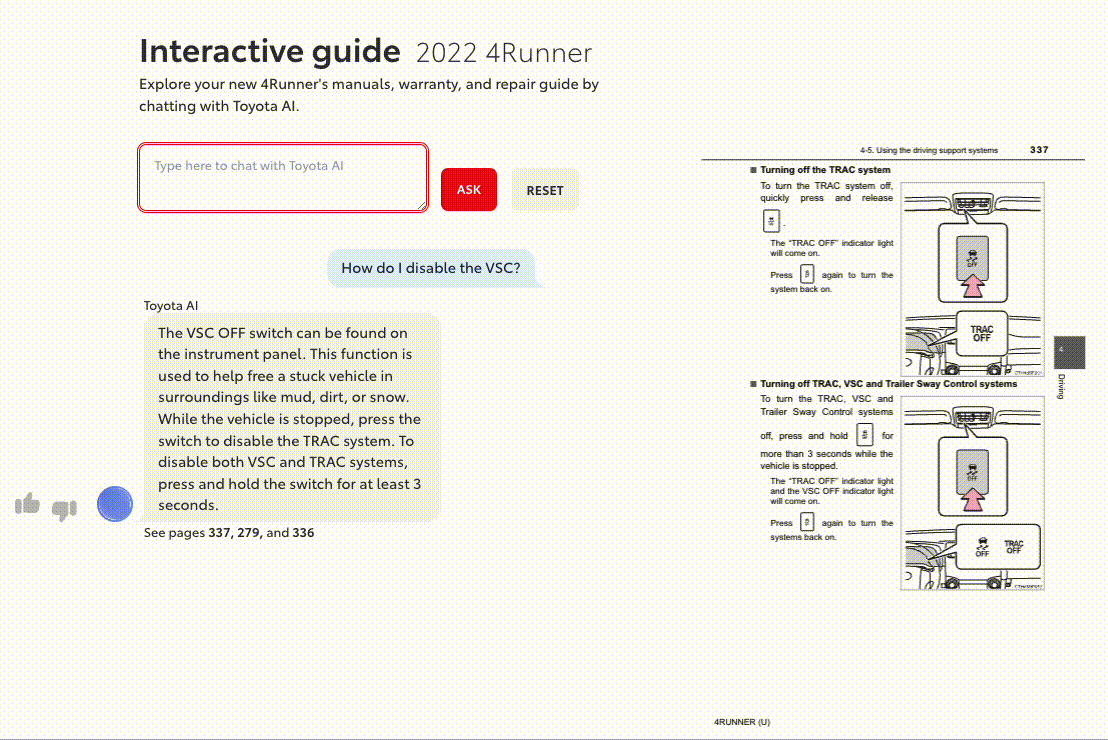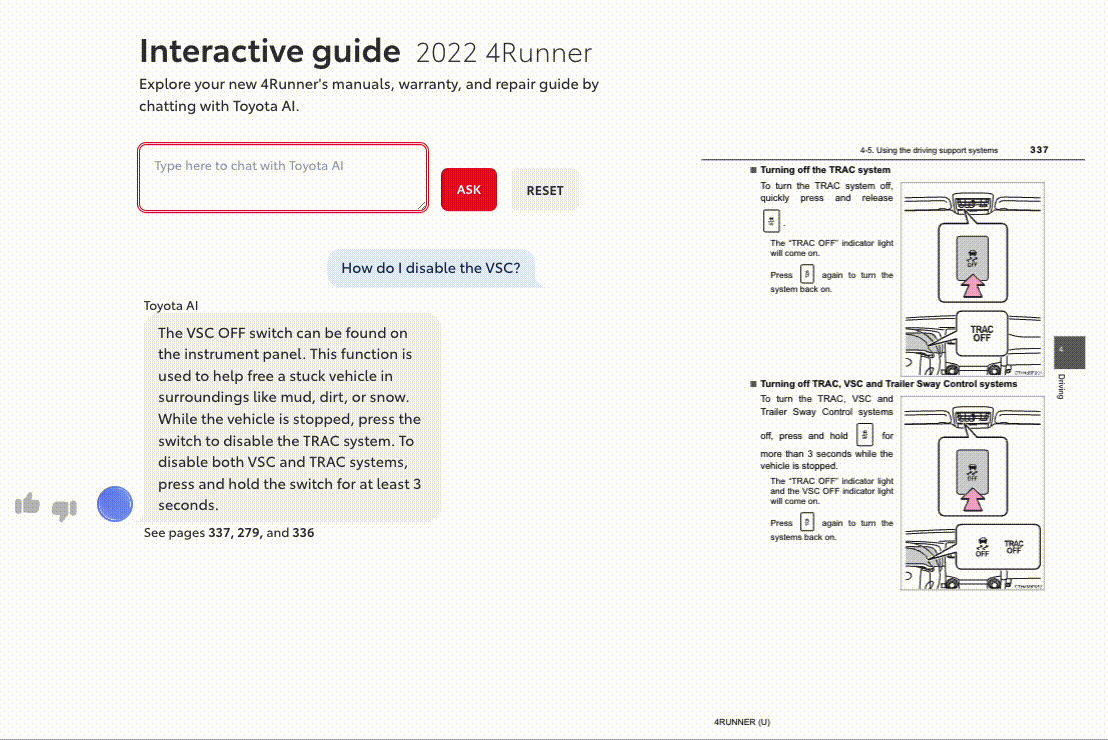
Question-Answering with LLMs
With the recent advancements in the state-of-the-art in natural language processing (NLP), we can do so much more to build an AI-powered voice interface that may be used for various applications, such as for assisting Toyota and Lexus owners. Our new approach incorporates state-of-the-art LLMs, similar to GPT-4, to improve the system's understanding of the vehicle owner's manual and its ability to answer complex questions more accurately.
Today, we can approach the question-answering task using two higher-level techniques. No more hand-labelled datasets, no more supervised learning! In the new system, the first frames the problem as a semantic search task, given a user's query which subdocument in the owner's manual represents the likely context containing the answer. Much in the same way, a human may use the index to find the relevant subchapter.
An example question: “How do I disable the VSC?”
We find a set of documents – in this case a few pages – that semantically contain relevant information to the topic.
The next step is to pass the relevant context to a large language model, using several chains of thought and epistemological prompts to guide a task such as “answer the users question based on information in the relevant sections.” The LLM generates token-by-token sequences capable of providing the user relevant information.
The next step is to pass the relevant context to a large language model, which uses various chain-of-thought and epistemological prompts to guide the task. The LLM generates token-by-token sequences capable of providing the user with relevant information, effectively answering their question.

Multi-Modal Learning
We are also exploring multi-modal learning, a promising approach that combines information from different sources, to enhance the accuracy and usefulness of the question-answering system. By incorporating computer vision techniques with NLP, we can analyze the images in the owner’s manual and extract relevant information to improve the system's responses. A multi-modal deep learning algorithm for question answering could work as follows: First, the textual and visual inputs would be pre-processed separately. For the textual input, we would use a pre-trained transformer-based language model to encode the input text and extract its most salient features. We would use a pre-trained convolutional neural network (CNN) to extract the relevant features from the images in the owner’s manual for the visual input.
Next, we would integrate the encoded textual and visual features using attention layers, which allow the model to focus on the most relevant parts of each input modality. Specifically, we would use multi-head attention, which involves splitting the features into multiple subspaces and performing attention separately on each subspace. This approach enables the model to capture more nuanced relationships between the textual and visual features. After the attention layers, the integrated features would be passed through several feedforward layers, which would learn to map the features to the final output. The output would be a sequence of tokens corresponding to the answer to the user's question.
In practice, this multi-modal deep learning algorithm could enable the system to analyze images in the owner's manual and provide more contextually relevant responses. For example, if a user asks a question about how to change a tire, the system could use computer vision to identify relevant images in the manual, extract features from those images using a pre-trained CNN and integrate those features with the textual input using attention layers. This approach can potentially provide users with an even more accurate and intuitive experience when using the question-answering system.
Another potential application is allowing the user to input their own photographs, in addition to a textual question, so that they can provide more context to the question-answering system. In this example, the user’s low oil pressure indicator lamp has illuminated, and they are able to ask the system for information with a picture and a basic question.

Bringing This to Life
In order to bring this service to Toyota and Lexus owners, we have built out the proof-of-concept version of the system shown in the screenshots above. This webapp is capable of interacting with the contents of a 2022 4Runner owner’s manual as well as the other owner’s documentation provided at the point of sale.
We are excited about working across the Toyota ecosystem to bring the latest advancements in AI and technology to benefit Toyota and Lexus drivers.
